HTTP Transport (parallel)¶
It is possible to run HTTP Transport in parallel. Workload may be distributed across multiple CPU cores and even across multiple servers.
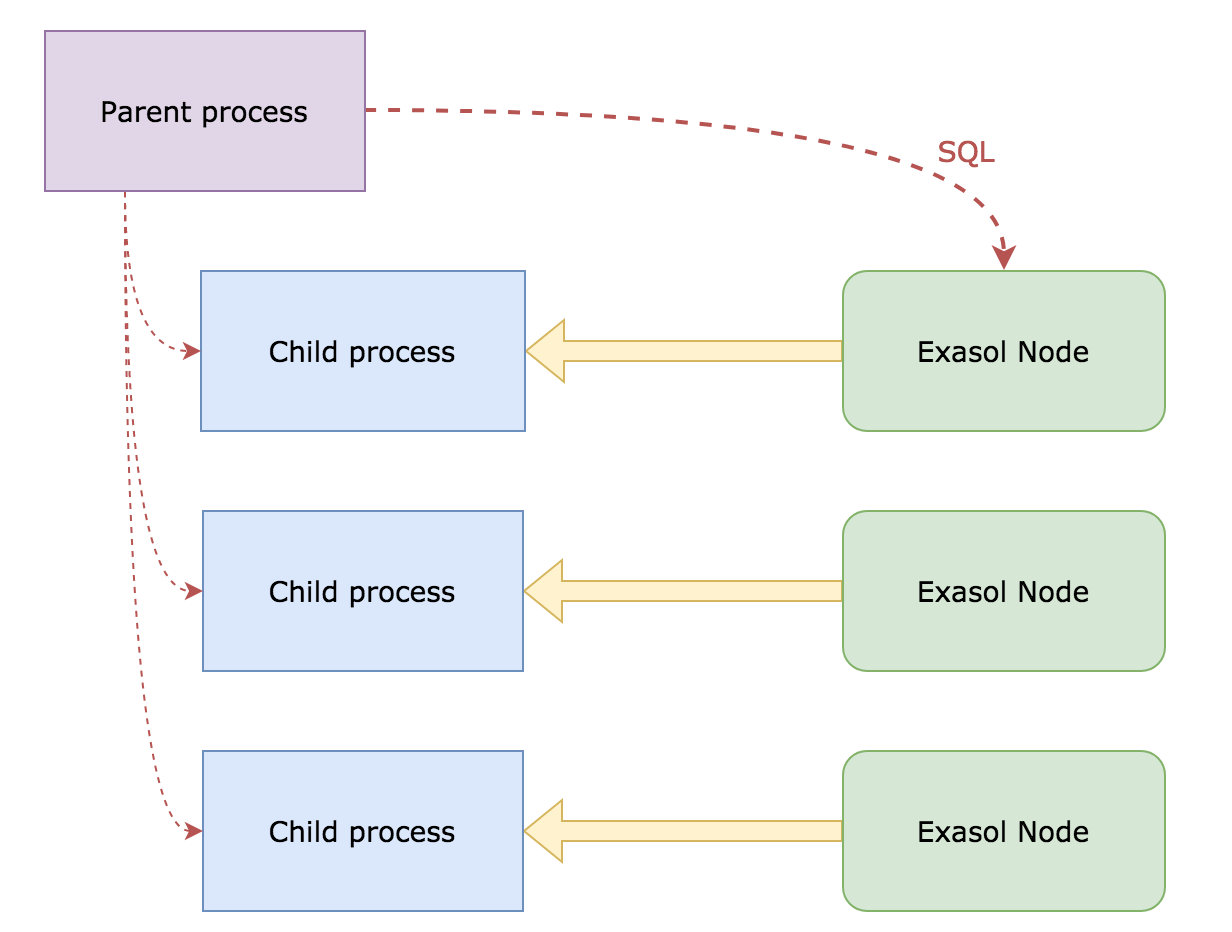
How it works on high level¶
Parent process opens main connection to Exasol and spawns multiple child processes.
Each child process connects to individual Exasol node using
http_transport()method, gets internal Exasol address (ipaddr:port/public_keystring) using the.exa_addressproperty, and sends it to the parent process.Parent process collects list of internal Exasol addresses from child processes and runs
export_parallel()orimport_parallel()function to execute SQL query.Each child process runs a callback function and reads or sends a chunk of data from or to Exasol.
Parent process waits for the SQL query and child processes to finish.
Please note that PyExasol does not provide any specific way to send internal Exasol address strings from child processes to parent process. You are free to choose your own way of inter-process communication. For example, you may use multiprocessing.Pipe.
Examples¶
b03_parallel_export.py>for EXPORT;b04_parallel_import.py>for IMPORT;b05_parallel_export_import.pyfor EXPORT followed by IMPORT using the same child processes;
Example of EXPORT query executed in Exasol¶
This is how the complete query looks from Exasol’s perspective.
EXPORT my_table INTO CSV
AT 'http://27.1.0.30:33601' FILE '000.csv'
AT 'http://27.1.0.31:41733' FILE '001.csv'
AT 'http://27.1.0.32:45014' FILE '002.csv'
AT 'http://27.1.0.33:42071' FILE '003.csv'
AT 'http://27.1.0.34:36669' FILE '004.csv'
AT 'http://27.1.0.35:36794' FILE '005.csv'
WITH COLUMN HEADERS
;